Last time, we walked through some of the history of quantum mechanics and came out with the Schrödinger Equation, the master equation of nonrelativistic quantum mechanics. Much of what we’ll do in this course will involve solving this equation in a variety of interesting cases; but before we begin, it’s worth plunging a bit more deeply into the equation itself and seeing what we can learn just from its structure. Among other things, we’ll see the relationship of the abstract vectors we get from the linear algebra approach to the functions we use in the differential-equation approach; see the (rather simple) way that real systems evolve over time; and encounter the fundamental limitations on measurement in quantum mechanics.
The relationship between vectors and functions
We wrote down the Schrödinger equation in terms of differential operators acting on functions:
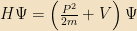
Here Ψ is a complex-valued wave function, and its magnitude squared can be interpreted as a probability — specifically, for any linear operator A built up out of X’s and P’s and so on,

We also identified some important operators:

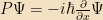

We didn’t write down the first equation last time, but it’s somewhat obvious, and I’m writing it for completeness; the X operator simply means “multiply by x.”
Let’s apply some of our linear algebra to these equations. Ψ is acting like a vector in the space of functions, so let’s explicitly denote it as a vector and write it as 
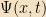
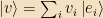

To see the details, let’s look more carefully at the eigenvectors of X. If we think about these as functions, then they must satisfy 

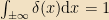
This function is an infinitely high spike centered at the origin.1 It satisfies the useful relationship

which follows directly from the definition; it’s the continuous analogue of the Kronecker delta 

These obviously form a basis for the set of functions on the real line. In fact, it’s not hard to expand any function in terms of them:

i.e., the function values 
Why did I bother with this? Well, because we can easily consider other bases, too. For example, the eigenfunctions of P satisfy
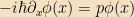
i.e.,

The subscript “p” simply indicates which eigenfunction we’re looking at.2 The fact that I’ve written these as functions is simply the expansion of the P eigenvectors in terms of the X eigenvectors:

So if I’m talking about some arbitrary state vector
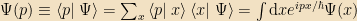
In the first step, I used the fact that 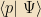




Now let’s look at our expression for expectation values. Rewritten in vector language, it says

(The expression of this as an integral simply follows from inserting two complete sets of x-states, on either side of the A. Exercise: Show this in detail)
Note, also, that using this probability interpretation there is a very clear interpretation of the meaning of 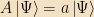


We’ll routinely move back and forth between the function (differential-equation) description and the algebra (state-vector) description, depending on which is more convenient.
The Uncertainty Principle
Now let’s the fact that operators — or at least, Hermitian operators, which have real eigenvalues — seem to correspond to physically observable quantities with our earlier demonstration that commuting operators share eigenvectors. This means that if two operators A and B commute, then
What happens if they don’t commute? Let’s assume that ![[A, B]\ne0](https://s0.wp.com/latex.php?latex=%5BA%2C+B%5D%5Cne0&bg=f2e1c3&fg=000000&s=0&c=20201002)

The second term is simply a number; this operator measures the deviation of a measurement of A from the mean. The expectation value of its square is the variation, a.k.a. the mean-square deviation:

The square root of this term is simply the standard deviation of measurements of A from the mean. (Note that, if 
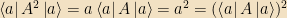

![\boxed{\left<(\Delta A)^2\right> \left<(\Delta B)^2\right> \ge \frac{1}{4}|\left<[A, B]\right>|^2}](https://s0.wp.com/latex.php?latex=%5Cboxed%7B%5Cleft%3C%28%5CDelta+A%29%5E2%5Cright%3E+%5Cleft%3C%28%5CDelta+B%29%5E2%5Cright%3E+%5Cge+%5Cfrac%7B1%7D%7B4%7D%7C%5Cleft%3C%5BA%2C+B%5D%5Cright%3E%7C%5E2%7D&bg=f2e1c3&fg=000000&s=0&c=20201002)
This is the Heisenberg uncertainty principle.3 Before we analyze it, let’s prove it. First, we prove the Cauchy-Schwarz inequality:

Exercise: Show this. Hint: Start from the fact that the norm of 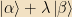
If we let 


Now note that
![\begin{array}{rcl} \Delta A \Delta B &=& \frac{1}{2}[\Delta A, \Delta B] + \frac{1}{2}(\Delta A \Delta B + \Delta B \Delta A) \\ &\equiv& \frac{1}{2}[\Delta A, \Delta B] + \frac{1}{2}\left\{\Delta A, \Delta B\right\} \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+%5CDelta+A+%5CDelta+B+%26%3D%26+%5Cfrac%7B1%7D%7B2%7D%5B%5CDelta+A%2C+%5CDelta+B%5D+%2B+%5Cfrac%7B1%7D%7B2%7D%28%5CDelta+A+%5CDelta+B+%2B+%5CDelta+B+%5CDelta+A%29+%5C%5C+%26%5Cequiv%26+%5Cfrac%7B1%7D%7B2%7D%5B%5CDelta+A%2C+%5CDelta+B%5D+%2B+%5Cfrac%7B1%7D%7B2%7D%5Cleft%5C%7B%5CDelta+A%2C+%5CDelta+B%5Cright%5C%7D+%5Cend%7Barray%7D&bg=f2e1c3&fg=000000&s=0&c=20201002)
(The latter quantity is called the anticommutator; these show up a lot in relativistic QM) Now, the commutator of two Hermitian operators is anti-Hermitian:
![\begin{array}{rcl} [A, B]^\dagger &=& (AB-BA)^\dagger\\&=&\left(B^\dagger A^\dagger - A^\dagger B^\dagger\right)\\&=&(BA - AB)\\&=&-[A, B]\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+%5BA%2C+B%5D%5E%5Cdagger+%26%3D%26+%28AB-BA%29%5E%5Cdagger%5C%5C%26%3D%26%5Cleft%28B%5E%5Cdagger+A%5E%5Cdagger+-+A%5E%5Cdagger+B%5E%5Cdagger%5Cright%29%5C%5C%26%3D%26%28BA+-+AB%29%5C%5C%26%3D%26-%5BA%2C+B%5D%5Cend%7Barray%7D&bg=f2e1c3&fg=000000&s=0&c=20201002)
and similarly, the anticommutator of two Hermitian operators is Hermitian. It’s trivial to see that the eigenvalues of any Hermitian operator must be real, and of an anti-Hermitian operator must be imaginary; simply write the operators in the basis where they are diagonal. That in turn implies that the expectation value of an (anti-)Hermitian operator must be real (imaginary), since we can expand 
![|\left<\Delta A \Delta B\right>|^2 = \frac{1}{4}|\left<[A, B]\right>|^2 + \frac{1}{4}|\left<\left\{A, B\right\}\right>|^2](https://s0.wp.com/latex.php?latex=%7C%5Cleft%3C%5CDelta+A+%5CDelta+B%5Cright%3E%7C%5E2+%3D+%5Cfrac%7B1%7D%7B4%7D%7C%5Cleft%3C%5BA%2C+B%5D%5Cright%3E%7C%5E2+%2B+%5Cfrac%7B1%7D%7B4%7D%7C%5Cleft%3C%5Cleft%5C%7BA%2C+B%5Cright%5C%7D%5Cright%3E%7C%5E2&bg=f2e1c3&fg=000000&s=0&c=20201002)
So now that we’ve proven the uncertainty principle, what does it mean? It means that, if two operators don’t commute, then no state can be in a simultaneous eigenket of both, or have a definite value of both; in fact, the product of the errors in measuring both of the quantities is bounded from below.
Let’s be concrete; take the operators X and P. Their commutator is easy to work out: for any 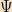
![[X, P]\Psi = -i\hbar\left(x \partial \Psi - \partial (x \Psi)\right) = +i\hbar \Psi](https://s0.wp.com/latex.php?latex=%5BX%2C+P%5D%5CPsi+%3D+-i%5Chbar%5Cleft%28x+%5Cpartial+%5CPsi+-+%5Cpartial+%28x+%5CPsi%29%5Cright%29+%3D+%2Bi%5Chbar+%5CPsi&bg=f2e1c3&fg=000000&s=0&c=20201002)
and thus ![[X, P] = i\hbar](https://s0.wp.com/latex.php?latex=%5BX%2C+P%5D+%3D+i%5Chbar&bg=f2e1c3&fg=000000&s=0&c=20201002)

You can physically visualize why this happens in terms of the explicit eigenfunctions we worked out earlier for X and P. If you are in an X-eigenstate, i.e. 

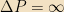
Exercise: Let 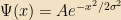


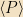
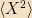


This form of Ψ is often referred to as a wave packet. It saturates the position-momentum uncertainty relationship, and is reasonably localized in space. (With the definition of “reasonably” being “within σ”) As such, it’s a very “particle-like” state for a system to be in.4
The uncertainty principle took many years for people to fully digest, and physicists spent a great deal of time5 trying to build thought experiments (and physical experiments) designed to defeat it, simultaneously measuring the position and momentum of a particle. In every case it failed; generally, the failure takes the form of the physical action required to measure one of the quantities disturbing the other quantity by a certain minimum amount. To take a simple example, consider Heisenberg’s original motivating example, using a microscope to measure the position and velocity of a particle. In order to see the particle, we must bounce a photon off of it. But the ability to resolve the particle’s position is bounded below by the wavelength, so we need 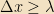

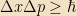
The Time-Independent Equation
Very often, the Hamiltonian has no explicit time dependence. In this case, it’s possible to separate the Schrödinger equation into two simpler equations. From a differential equation perspective, we can separate the variables by conjecturing that we can write 

Dividing both sides (on the left, if you want to be careful) by 

The left-hand side of this equation is a function only of x; the right-hand side, only of t. The only way these two functions can therefore be equal to one another is if they’re both equal to a constant, which we’ll denote by E. (This will be our one exception to the constants-are-lowercase rule) The right-hand side is now simple to solve:
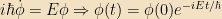
The left-hand side is
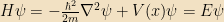
This is the time-independent Schrödinger equation, and is generally much easier to solve than the time-dependent version. We can immediately see that it is simply an eigenvalue equation for H; and knowing that H is our Hamiltonian, we can immediately interpret the physical meaning of E as the energy of the state.
Time Evolution
If we write down the Schrödinger equation for a time-independent Hamiltonian in vector notation,

we can solve it in a very formal sense:
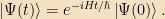
The exponential of an operator is simply defined by its Taylor series; if you write out the infinite sum, it’s obvious that this solves the differential equation. The operator on the right-hand side is known as the time-evolution operator, 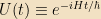

where n is some index that runs over the eigenvectors of H. Then
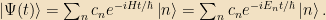
This is how kets evolve over time. Note that if 
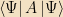
If on the other hand
Note one other thing: For any observable A, 
![[H, A] = 0](https://s0.wp.com/latex.php?latex=%5BH%2C+A%5D+%3D+0&bg=f2e1c3&fg=000000&s=0&c=20201002)
![[U(t), A] = 0](https://s0.wp.com/latex.php?latex=%5BU%28t%29%2C+A%5D+%3D+0&bg=f2e1c3&fg=000000&s=0&c=20201002)

Proof: By Taylor expansion,
For this to vanish for every t, the coefficient of each power of t must vanish independently; but the coefficient of 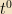
![\frac{i}{\hbar}[A, H]](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bi%7D%7B%5Chbar%7D%5BA%2C+H%5D&bg=f2e1c3&fg=000000&s=0&c=20201002)
Thus an operator corresponds to a conserved quantity if and only if it commutes with the Hamiltonian. This means that sets of commuting observables which include the Hamiltonian are particularly interesting; they represent sets of simultaneously measurable conserved quantities. Maximal sets of commuting observables are even more interesting; if two eigenkets of such a set have the same eigenvalues under each operator, then (by definition) there is no other quantity which we could measure which would distinguish the two; the two kets must correspond to the same physical state. We can therefore label the eigenkets of such a CSCO by their eigenvalues under each of the operators, and those labels form a complete description of the state of the system in each eigenket. This relatively simple statement will turn out to have profound implications later — in quantum mechanics, when two particles are identical, they’re really identical.
Next Time: A concrete example: The two-state system and nuclear magnetic resonance.
1 Dirac proposed this “function” for exactly this purpose, and mathematicians proceeded to spend decades arguing over whether or not it was a bona fide function. This required some careful rethinking of the definition of functions, some work in measure theory, and so on, and the practical upshot was that yes, this whole thing works just fine. Physicists pretty much ignored the entire controversy.
2 Note that these eigenfunctions aren’t normalized; 

3 Heisenberg considered this his most important discovery; the equation — specialized to the case of x and p — is carved on his tombstone.
4 The entire discussion over “particle-wave duality” was an artifact of the confusion in the early 20th century, especially in the aftermath of de Broglie’s paper, when the two concepts were considered to have very distinct physical meanings. From a modern perspective, the distinction is purely semantic. A system is in a “particle-like” state when it has a fairly definite value of position, i. e. 

5 Bohr and Einstein famously spent extraordinary amounts of time, especially at the Copenhagen conference in 1925, debating these; every day, Einstein would come up with a (generally extremely subtle) objection to the quantum results, and Bohr would (after much hand-wringing) come back with an explanation. Reading up on their debates is fascinating.
6 Note that we can still define 



more copyediting nits, I’m afraid: with your CSS layout, the anticommutator and commutator equation gets cut off (in both Firefox and Chrome, at least); also, you’re missing a $ in the latter part of the paragraph, so the $ \TeX $ isn’t rendering.
Thanks! Fixed.