And now for the first contentful post about quantum mechanics. It’s wild, wonderful, exciting… okay, not really. It’s the mathematical prelude, an overview of some key physical constants and some key bits of linear algebra which we’ll use rather extensively going forwards. This isn’t meant to be deep, or to be an introduction to linear algebra; it’s a way to establish the notations we’ll be using, and to point out the facts which will happen to be important to us later on.
Some useful numbers
The fundamental physical constant associated with Quantum Mechanics is Planck’s constant, 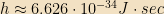


Our unit of length will be the Angstrom, 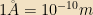
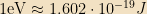



Atomic binding energies are generally on the order of a few eV; the weak hydrogen-hydrogen bonds used in biological systems are a few meV; nuclear binding energies are a few MeV. The largest particle accelerators have beam energies on the order of tens of TeV per particle; the most energetic cosmic ray ever observed was a proton with an energy of about 
A bit of linear algebra
Bibliographic note: My favorite more detailed text on this subject is chapter 1 of Sakurai. If you’re of a somewhat mathematical bent, that book is a great place to start.
And now for a lightning review of linear algebra. This is not meant to teach you linear algebra; if you tried to learn it from this, your head would probably explode. It’s just a way for me to review the key points, describe the rather oddball notation that we use in quantum mechanics, and point out a few key facts which we’ll use over and over later on. The hope is that you’ll read over this and say “yeah, yeah, obvious… incomprehensible, but obvious… blah blah… ok.” If you don’t say that, then stop me and ask, because this part needs to be clear. (Also, if you need a linear algebra refresher, the Wikipedia articles are an OK place to start)
Vector spaces, kets: A vector space is any collection of objects which can be added and multiplied by numbers. (aka, scalars) In quantum mechanics, we will generally be concerned with complex vector spaces, i.e. ones where these constants are complex numbers. Some common examples of vector spaces are the space of vectors in the plane, and the space of functions on the real line. We will denote the vector named “x” by 
Inner products, bras, adjoints: All of the vector spaces we will be interested in are inner product spaces — i.e., there is an inner (dot) product which takes two vectors and gives a scalar. But we’re going to be a bit more careful than this standard statement. Instead, we’ll say this: For every vector space, there exists a dual vector space; this is the pairing of column vectors to row vectors. These row vectors are denoted by 


In simpler terms, the dagger is the complex conjugate of the transpose. For complex vector spaces, this dagger will take the place of the ordinary transpose everywhere. We define the inner (dot) product to be a product of a bra and a ket: 
For vectors on a plane, if 



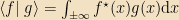
Note that this doesn’t actually work as an inner product over arbitrary functions, since the integral could diverge; so the interesting inner product space is the space of square-integrable functions, i.e. the set of functions for which this integral is finite. We’ll use this space all the time.
The norm of a vector is the square root of its dot product with itself. The formal definition of an inner product also states that every vector must have nonnegative norm, and only the zero vector has norm zero. See the Wikipedia page for more about inner products if you want details.
In QM you’ll often see the term “Hilbert space” bandied about. Technically, a Hilbert space is an inner product space which is Cauchy-complete; in practice, fewer than one physicist in fifty could probably tell you that definition from memory, because it’s of very little practical use in QM. However, it does turn out that all of the vector spaces we’ll be interested really are Hilbert spaces, and so they are commonly referred to as such and are often denoted by 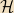
Operators: A linear operator (or just “operator” for short) on a vector space is something which maps vectors onto other vectors, which is linear. (i.e., a matrix, but for general vector spaces they’re typically called operators) We’ll denote operators by capital Roman letters, so 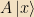
![[A, B] = AB - BA](https://s0.wp.com/latex.php?latex=%5BA%2C+B%5D+%3D+AB+-+BA&bg=f2e1c3&fg=000000&s=0&c=20201002)
Note that if you multiply a ket and a bra in the “wrong order,” you get an operator; you can tell that from the fact that when you multiply it by a ket on the right, you get a ket back.
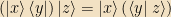
Operators can be acted on with daggers, too: that dagger is defined by 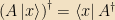

Operators on vectors in a plane are simply 2×2 matrices. Operators on the space of functions are linear operators; e.g., derivatives are linear operators. The product of two operators is an operator, so 

An operator is called “Hermitian” if 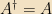
![[A, A^\dagger] = 0](https://s0.wp.com/latex.php?latex=%5BA%2C+A%5E%5Cdagger%5D+%3D+0&bg=f2e1c3&fg=000000&s=0&c=20201002)

Hermitian 2×2 matrices have the form 
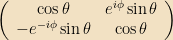
Since we can form polynomials out of operators, we can also form functions of them (or at least, analytic functions of them) by means of Taylor series. One thing that we will do particularly often is exponentiate. A useful fact is that, if ![[A, B] = 0](https://s0.wp.com/latex.php?latex=%5BA%2C+B%5D+%3D+0&bg=f2e1c3&fg=000000&s=0&c=20201002)
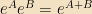
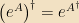



Bases: Probably the most important theorem of linear algebra is the Gram-Schmidt theorem, which says that every inner product space has an orthonormal basis. A basis is a set of vectors, which are linearly independent (i.e., no vector in that set can be written as a linear combination of the others) and such that every vector in the entire vector space can be written as a linear combination of those basis vectors; orthonormal means that these basis vectors are orthogonal (the inner product of any two different basis vectors is zero) and normal. (The norm of each basis vector is 1) Each vector space has in fact an enormous variety of bases; but the number of elements in the basis is a constant for any particular vector space, and that number is the dimension of the vector space.
A basis for the set of vectors in the plane is 


Given a basis, any vector can be written as its “basis expansion,” i.e. the set of coefficients by which you need to multiply each basis vector in order to get that vector — that’s really what we refer to when we write out a column vector as a column of numbers. Probably the most useful equation you can write about a basis is that, if the 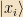

(This is easy to see: Write an arbitrary vector 

Bases are by no means unique. In fact, if the set of 
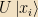

Then 

Thus every unitary operator can be thought of as a change of basis.
If we expand vectors in terms of their basis coefficients, we can also expand operators in the same way. (Which is what we mean when we write out matrices as arrays of numbers) The matrix elements of an operator A are simply 


Eigen(values, vectors): If 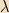

These will turn out to be of tremendous importance in QM. The Spectral Theorem says that, if A is Hermitian, then not only does it have eigenvectors, but the set of its eigenvectors forms a basis of the vector space; i.e., there are as many linearly independent, orthonormal eigenvectors as there are dimensions in the space. This is typically referred to as the “eigenbasis” of A. If the eigenvalues of A are 

If on the other hand we have the eigenvectors of A written in some other basis, then we can form a unitary matrix by simply stuffing the eigenvectors into the columns of a matrix 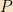
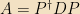

The standard way to find the eigenvalues of a (finite-dimensional) matrix is to note that the eigenvalue equation can be rewritten as 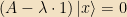
Example: Let 

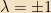
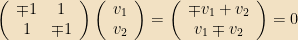
And thus 

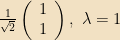

The unitary matrix that moves from the basis in which we originally wrote A into the eigenbasis is simply
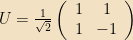
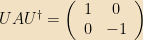
Note that, if two eigenvectors have the same eigenvalues, then any linear combination of those two eigenvectors is also an eigenvector with that eigenvalue. (i.e., the eigenbasis isn’t unique; we can rotate any eigenvector into any other eigenvector and it’s still an eigenbasis)
When we work with an eigenbasis, we will customarily label the basis vectors by their eigenvalues — i.e., 
One of the most important facts about eigenvectors in quantum mechanics is that, if any two Hermitian operators A and B commute, then they have the same set of eigenvectors. (Although they may — will! — have different eigenvalues for each of those vectors. A and B need not even have the same units.)
Proof: Let 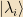
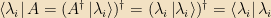

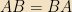
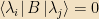
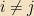
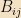
The useful consequence of this theorem is: We will typically find ourselves with some collection of Hermitian operators “of interest” in a particular problem. We can always pick some maximal commuting subset of that set. (i.e., adding any more operators would mean that some pair of them don’t commute) The simultaneous eigenvectors of that set — which we will call a “complete set of commuting observables,” or CSCO for short, for reasons to be seen next time — will be our basis of choice in most matters, and we will label the vectors by their various eigenvalues 
This concludes the extremely rapid review of linear algebra. Wasn’t that fun?
Next time: Something completely different: Actual quantum physics!
1 Pronounced “aitch-bar.”
2 So you can combine a “bra” and a “ket” to form a “bracket.” And now you have seen an example of Paul Dirac’s sense of humor. Yes, that really is how he came up with those names.
3 The Spectral Theorem actually only requires that A be normal; if A isn’t Hermitian, the eigenvalues may be complex. But we won’t need that fact.



Not using natural units?
Nope. I find it gets fairly confusing to do that in intro courses; better to make the various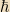 ‘s and c’s explicit.
‘s and c’s explicit.